整数長ジョブシーケンス問題#
ここではJijZeptSolverとJijModelingを用いて、長さが整数のジョブシーケンス問題を解いてみましょう。 この問題は、Lucas, 2014, “Ising formulations of many NP problems”の6.3. Job Sequencing with Integer Lengthsでも触れられています。
整数長ジョブシーケンス問題とは#
タスク1は1時間の実行時間、タスク2は3時間の実行時間、のように、整数長のタスクがいくつかあるような場合を考えましょう。 「これらのタスクを複数コンピュータに分散させる場合、偏りを生じさせることなく、これらのコンピュータの実行時間を最適に分散させるにはどうすれば良いか?」を求める問題です。
例#
次のような問題を考えてみましょう。
10個のタスクを、3台のコンピュータに分散させることを考えましょう。 10個のタスクの長さはそれぞれ、1, 2, …, 10であるとします。 私たちの目的は、3つのコンピュータの最大実行時間を、最小化するような解を求めることです。 この場合、最適解は\(\{1, 2, 7, 8\}, \{3, 4, 5, 6\}, \{9, 10\}\)などがあり、この場合のコンピュータ実行時間の最大値は19となります。
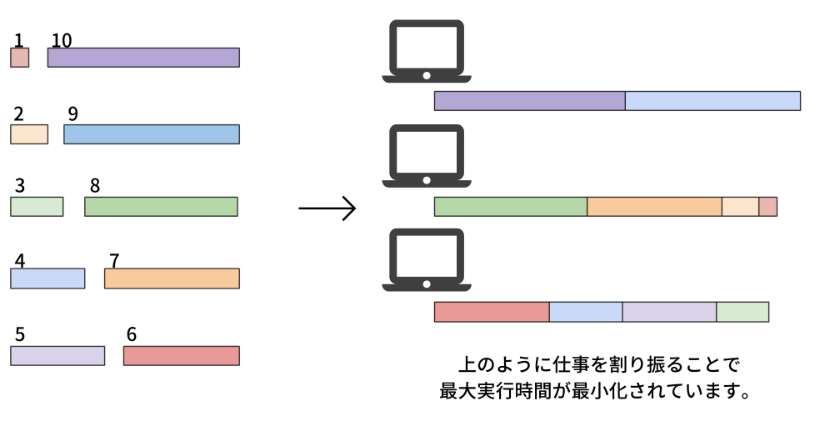
一般化#
次に、\(N\)個のタスク(\(\{0, 1, \dots, N-1\}\))について考えることにしましょう。 これらのタスクの実行時間は\(L= \{L_0, L_1, \dots, L_{N-1}\}\)とします。 \(M\)個のコンピュータが与えられたとき、\(j\)番目のコンピュータに割り当てられたタスクの集合を\(V_j\)としたとき、\(j\)番目のコンピュータに割り当てられたタスクの総実行時間は\(A_j = \sum_{i \in V_j} L_i\)のようになります。 そして\(i\)番目のタスクを\(j\)番目のコンピュータに割り当てるとき1、そうでないとき0となるバイナリ変数を\(x_{i, j}\)のように書くことにしましょう。
制約: 各タスクはいずれか1つのコンピュータに割り当てられなければならない
例えば、5番目のタスクを、1番目と2番目のコンピュータに同時に割り当てることはできません。 これを数式で表現すると、以下のようになります。
目的関数: 0番目のコンピュータと他のコンピュータとの層実行時間の差を最小化する
0番目のコンピュータの総実行時間を基準として扱い、それと他のコンピュータとの差を最小化することを考えましょう。 これにより、実行時間のばらつきが小さくなり、タスクが均等に分散されます。
JijModelingを用いたモデル化#
次に、JijModelingを用いた実装を説明します。 まずは上述の数理モデルで用いる変数を定義しましょう。
import jijmodeling as jm
# defin variables
L = jm.Placeholder('L', ndim=1)
N = L.len_at(0, latex="N")
M = jm.Placeholder('M')
x = jm.BinaryVar('x', shape=(N, M))
i = jm.Element('i', belong_to=(0, N))
j = jm.Element('j', belong_to=(0, M))
Lは各タスクの実行時間を表す1次元配列です。
Nはタスク数を表します。
Mはコンピュータの数を表します。
そして、\(x\)は2次元のバイナリ変数列を表します。
最後に、数理モデルで用いる添字i, jを設定します。
制約#
式(1)の制約を実装しましょう。
# set problem
problem = jm.Problem('Integer Jobs')
# set constraint: job must be executed using a certain node
problem += jm.Constraint('onehot', x[i, :].sum()==1, forall=i)
x[i, :].sum()はsum(j, x[i, j])の糖衣構文です。
目的関数#
次に、式(2)の目的関数を実装します。
# set objective function: minimize difference between node 0 and others
A_0 = jm.sum(i, L[i]*x[i, 0])
A_j = jm.sum(i, L[i]*x[i, j])
problem += jm.sum((j, j!=0), (A_0 - A_j) ** 2)
sum((j, j!=0), ...)は\(j \neq 0\)以外の\(j\)で総和を取ることを意味します。
実装した数理モデルを、Jupyter Notebook上で表示してみましょう。
problem
インスタンスの準備#
各ジョブの実行時間と、コンピュータ数を設定しましょう。 ここでは、先ほど述べた10個のタスクと3台のコンピュータの場合を用います。
# set a list of jobs
inst_L = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# set the number of Nodes
inst_M = 3
instance_data = {'L': inst_L, 'M': inst_M}
JijZeptSolverで解く#
jijzept_solverを用いて、この問題を解いてみましょう。
import jijzept_solver
interpreter = jm.Interpreter(instance_data)
instance = interpreter.eval_problem(problem)
solution = jijzept_solver.solve(instance, time_limit_sec=1.0)
解の可視化#
最後に、得られた解を可視化してみましょう。
import matplotlib.pyplot as plt
import numpy as np
df = solution.decision_variables_df
x_indices = df[df["value"]==1]["subscripts"].to_list()
# get the instance information
L = instance_data["L"]
M = instance_data["M"]
# initialize execution time
exec_time = np.zeros(M, dtype=np.int64)
# compute summation of execution time each nodes
for i, j in x_indices:
plt.barh(j, L[i], left=exec_time[j],ec="k", linewidth=1,alpha=0.8)
plt.text(exec_time[j] + L[i] / 2.0 - 0.25 ,j-0.05, str(i+1),fontsize=12)
exec_time[j] += L[i]
plt.yticks(range(M))
plt.ylabel('Computer numbers')
plt.xlabel('Execution time')
plt.show()
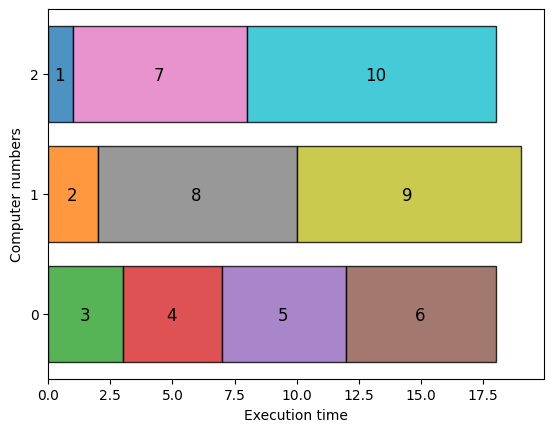
可視化されたグラフから、実行時間が3台のコンピュータに分散されていることがわかります。 この場合の実行時間の最大値は19であることから、最適解が得られていることもわかります。